






Unlocking ai potential the benefits and applications of retrieval augmented generation – Unlocking AI potential: the benefits and applications of retrieval augmented generation (RAG) are revolutionizing how we interact with artificial intelligence. Forget those clunky, sometimes inaccurate AI bots – RAG is a game-changer. By connecting AI models to vast knowledge bases, RAG ensures factual accuracy and dramatically reduces the infamous “hallucinations” that plague traditional generative AI. This isn’t just a tech upgrade; it’s a leap forward, impacting everything from healthcare diagnostics to financial modeling, and opening doors to applications we haven’t even imagined yet. Prepare to dive into the world where AI gets smarter, faster, and more reliable, thanks to the power of RAG.
This exploration will delve into the core mechanics of RAG, comparing it to older AI models and highlighting its key advantages. We’ll examine its impact across diverse industries, showcasing real-world examples and exploring the technical aspects of implementation. We’ll also address the challenges and ethical considerations, paving the way for a discussion of RAG’s future trajectory and potential.


Introduction to Retrieval Augmented Generation (RAG): Unlocking Ai Potential The Benefits And Applications Of Retrieval Augmented Generation

Source: medium.com
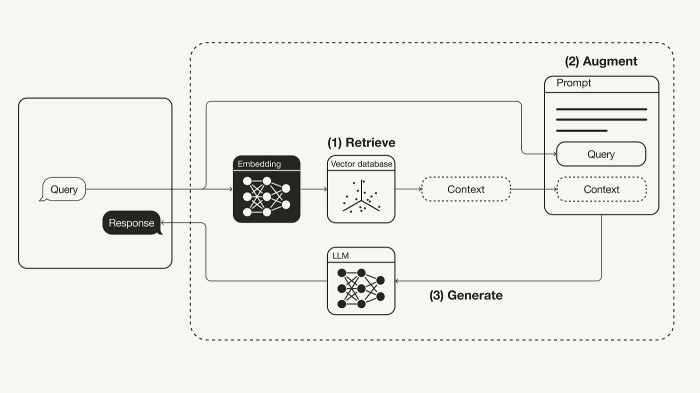
Forget the AI that just hallucinates facts – meet Retrieval Augmented Generation (RAG), the AI upgrade that’s bringing a much-needed dose of reality to the party. RAG isn’t your average generative AI; it’s a game-changer, cleverly combining the creative power of generative models with the grounded accuracy of external knowledge bases. Think of it as giving your AI a super-powered memory and a hefty research assistant all rolled into one.
RAG fundamentally differs from traditional generative AI models in its approach to information. Traditional models, like large language models (LLMs), generate text based solely on the data they were trained on. This can lead to impressive-sounding but factually inaccurate outputs, a phenomenon known as “hallucination.” RAG, however, actively searches and retrieves relevant information from external sources – think databases, documents, or even the entire internet – before generating its response. This allows it to ground its output in real-world data, making it far more reliable and accurate.
Advantages of RAG in Enhancing AI Capabilities
The benefits of RAG are numerous and impactful. By incorporating external knowledge, RAG significantly improves the accuracy and factual consistency of AI-generated content. This is crucial for applications where accuracy is paramount, such as legal research, medical diagnosis support, or financial analysis. Furthermore, RAG allows AI systems to access and process a far broader range of information than they could ever be trained on directly. This unlocks new possibilities for complex tasks that require up-to-date and specific knowledge, moving beyond the limitations of static training datasets. Finally, RAG enhances the explainability and trustworthiness of AI outputs. By citing its sources, RAG provides transparency into its reasoning process, building confidence in its results and facilitating easier debugging or verification.
A Brief History of RAG
While the core concepts behind RAG have existed for some time, its recent surge in popularity is largely due to advancements in both generative AI models and efficient information retrieval techniques. Early forms of RAG-like systems can be traced back to systems that used knowledge bases to augment rule-based AI. However, the modern iteration of RAG emerged with the rise of powerful LLMs and readily available, large-scale knowledge sources. The combination of these advancements allowed for the creation of practical and scalable RAG systems capable of handling complex tasks and large volumes of information. The development of efficient embedding techniques, which represent information in a way that allows for fast similarity searches, has been particularly crucial to the success of RAG. This has allowed for quicker and more relevant information retrieval, a critical component of any effective RAG system.
Benefits of RAG in Enhancing AI Performance
Retrieval Augmented Generation (RAG) is revolutionizing AI, offering a significant leap forward in accuracy and reliability. By grounding generative models in external knowledge bases, RAG tackles the inherent limitations of traditional models, leading to more trustworthy and insightful outputs. This enhancement isn’t just a minor improvement; it’s a paradigm shift that unlocks the full potential of AI in various fields.
Improved Accuracy and Factual Consistency Through RAG
RAG significantly improves the accuracy and factual consistency of AI-generated content. Traditional generative models, trained solely on massive datasets, can sometimes produce outputs that are factually incorrect or nonsensical – a phenomenon known as “hallucination.” RAG mitigates this by allowing the model to access and reference external sources of information before generating a response. This ensures that the generated content aligns with established facts and avoids the pitfalls of fabricated information. The model essentially checks its work against a reliable knowledge base, making it far more trustworthy.
RAG’s Impact on Hallucinations in Generative AI
Hallucinations, a common problem in large language models (LLMs), involve the generation of plausible-sounding but entirely fabricated information. This can be particularly problematic in applications requiring accuracy, such as medical diagnosis or financial analysis. RAG directly addresses this issue by providing the model with access to a verified knowledge base. Instead of relying solely on its internal training data, the model can retrieve relevant information from external sources, ensuring that its responses are grounded in reality. This drastically reduces the likelihood of hallucinations, making the AI more reliable and trustworthy.
Performance Comparison: RAG-Enhanced vs. Traditional Models
Consider the task of answering complex factual questions. A traditional LLM might attempt to answer based solely on its training data, potentially resulting in inaccurate or incomplete responses. A RAG-enhanced model, however, can access and process information from a vast knowledge base, providing a much more comprehensive and accurate answer. In scenarios demanding precise information retrieval and synthesis, the performance difference is stark. For instance, in legal research, where precise referencing and accuracy are paramount, RAG-enhanced models significantly outperform traditional models by minimizing the risk of misinterpretations and providing verifiable sources for claims.
Real-World Applications of RAG and Their Benefits and Challenges
The benefits of RAG are already being realized across various sectors. The following table illustrates three distinct applications, highlighting their advantages and challenges:
| Application | Benefit 1 | Benefit 2 | Challenge |
|---|---|---|---|
| Customer Service Chatbots | Improved accuracy in answering customer queries, reducing frustration and improving customer satisfaction. | Ability to access and provide real-time information from company databases and knowledge bases. | Maintaining the up-to-date nature of the knowledge base and ensuring consistent data quality. |
| Medical Diagnosis Support | Enhanced accuracy in identifying potential diagnoses by cross-referencing patient data with medical literature and research. | Reduced reliance on a doctor’s memory, leading to more comprehensive and informed diagnoses. | Ensuring data privacy and compliance with regulations related to patient health information. |
| Financial Analysis and Reporting | More accurate and reliable financial reports generated by accessing and processing real-time market data and financial statements. | Improved decision-making by providing more context and reducing the risk of errors in financial forecasts. | The need for sophisticated data integration and management systems to handle large volumes of financial data. |
Applications of RAG Across Various Industries

Source: edu.hk
Retrieval Augmented Generation (RAG) isn’t just a buzzword; it’s revolutionizing how we interact with information and leverage AI. Its ability to seamlessly combine the power of large language models with the precision of external knowledge bases is transforming various sectors, boosting efficiency and unlocking new possibilities. Let’s dive into some key areas where RAG is making a real impact.
RAG in Healthcare
The healthcare industry, drowning in a sea of patient data, research papers, and medical guidelines, is a prime candidate for RAG’s transformative power. By connecting LLMs with vast medical databases, RAG can significantly improve diagnosis accuracy, personalize treatment plans, and accelerate drug discovery.
- Faster and More Accurate Diagnosis: RAG can analyze patient symptoms, medical history, and relevant research to suggest potential diagnoses, aiding doctors in making quicker and more informed decisions.
- Personalized Treatment Plans: By accessing a patient’s unique data and combining it with the latest research, RAG can help create tailored treatment plans, optimizing outcomes and minimizing side effects. For example, a system could suggest specific dosages based on a patient’s genetic profile and medical history.
- Accelerated Drug Discovery: RAG can sift through massive datasets of research papers and clinical trials to identify potential drug candidates and predict their efficacy, significantly speeding up the drug development process.
RAG in Finance
The financial industry, with its complex regulations and massive data volumes, can leverage RAG to improve risk management, enhance customer service, and automate various processes.
- Improved Fraud Detection: RAG can analyze transaction data and identify patterns indicative of fraudulent activity, flagging suspicious transactions for human review. Imagine a system that instantly recognizes unusual spending patterns based on a customer’s past behavior and location.
- Enhanced Customer Service: RAG-powered chatbots can provide accurate and personalized financial advice, answering customer queries efficiently and resolving issues quickly. This can free up human agents to handle more complex tasks.
- Automated Report Generation: RAG can automate the creation of financial reports, pulling data from various sources and generating comprehensive summaries, saving significant time and resources.
RAG in Education
Education is another sector ripe for disruption by RAG. By providing personalized learning experiences and automating administrative tasks, RAG can enhance the learning process for both students and educators.
- Personalized Learning: RAG can tailor educational content to individual student needs, providing customized learning paths and resources. Imagine a system that adapts the difficulty level of a lesson based on a student’s performance.
- Automated Essay Grading: While not perfect, RAG can assist in grading essays, providing feedback on grammar, style, and content, freeing up educators’ time for more personalized interaction with students.
- Intelligent Tutoring Systems: RAG can power intelligent tutoring systems that provide students with personalized support and guidance, adapting to their individual learning styles and pace.
RAG in the Legal Industry: A Hypothetical Application
While already seeing use in legal research, a future application of RAG could be in predictive legal analysis. Imagine a system that analyzes legal precedents, statutes, and case law to predict the likely outcome of a case, considering various factors like jurisdiction and specific details.
The benefits are clear: improved case strategy, more accurate estimations of legal risk, and potentially reduced litigation costs. However, challenges include ensuring the accuracy and fairness of the predictions, addressing potential biases in the data, and ensuring compliance with legal and ethical standards. The legal profession’s reliance on precedent and nuanced interpretation makes this a complex but potentially transformative area for RAG.
Technical Aspects of Implementing RAG
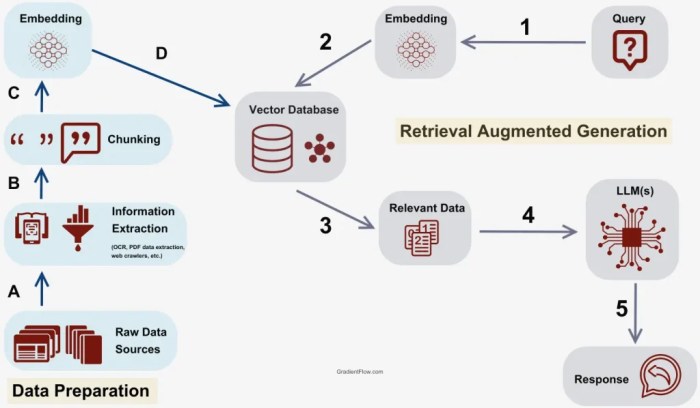
Building a Retrieval Augmented Generation (RAG) system isn’t just about throwing some code together; it’s about carefully orchestrating several key components to achieve seamless information retrieval and generation. Understanding these components and the intricacies of their interaction is crucial for building a truly effective RAG system. This section dives into the technical nuts and bolts, providing a practical understanding of the process.
At its core, a RAG system involves three main components: the retriever, the generator, and the knowledge base. The retriever acts like a highly efficient librarian, quickly sifting through your knowledge base to find the most relevant information in response to a user query. The generator, then, acts as a skilled writer, taking this retrieved information and crafting a coherent and informative response. Finally, the knowledge base serves as the vast library itself, containing all the information the system can access.
Retrieval Methods in RAG
Various retrieval methods exist, each with its strengths and weaknesses. The choice of method significantly impacts the efficiency and accuracy of the RAG system. For instance, -based search is simple to implement but can be prone to retrieving irrelevant information due to ambiguity or lack of contextual understanding. Semantic search, on the other hand, leverages the meaning behind words, leading to more precise retrieval. Vector databases, using techniques like embedding, offer a sophisticated approach, capturing the relationships between different pieces of information for more nuanced retrieval. Consider a scenario where a user asks about “the best way to treat a headache.” A -based search might return unrelated articles on headaches in the context of brain surgery, while a semantic search would likely prioritize articles focusing on home remedies or over-the-counter pain relief.
Step-by-Step Implementation of a Simple RAG System
Implementing a basic RAG system involves a series of steps. While the complexity can scale significantly depending on the application and data volume, understanding the foundational steps is key.
A simplified implementation process might look like this:
- Define the Knowledge Base: Choose the source of your information. This could be a collection of documents, a database, or even a set of web pages. Ensure the data is clean and well-structured.
- Data Preprocessing: Clean and structure your data. This involves tasks like removing duplicates, handling missing values, and potentially converting data into a suitable format for the retriever (e.g., text embeddings).
- Choose a Retriever: Select an appropriate retrieval method. For a simple system, a -based search or a basic vector database might suffice. More complex systems might benefit from advanced techniques like dense passage retrieval.
- Implement the Retriever: Develop the code that will take a user query and retrieve relevant information from the knowledge base based on your chosen method.
- Choose a Generator: Select a large language model (LLM) or another text generation model that will use the retrieved information to create the final response.
- Integrate Retriever and Generator: Connect the retriever and generator so that the generator receives the retrieved information as input and generates the response.
- Test and Iterate: Thoroughly test the system and refine it based on the results. This iterative process is crucial for optimizing performance and accuracy.
Importance of Data Quality and Preprocessing
The adage “garbage in, garbage out” is particularly relevant to RAG systems. The quality of the knowledge base directly impacts the quality of the generated responses. Preprocessing steps, such as cleaning the data, handling inconsistencies, and structuring information effectively, are critical. Imagine a knowledge base with numerous spelling errors, inconsistent formatting, and irrelevant information. The retriever would struggle to find relevant information, and the generator would produce inaccurate or nonsensical responses. Robust data preprocessing is essential for ensuring the system’s accuracy and reliability. A well-preprocessed knowledge base ensures that the retriever can efficiently identify and retrieve relevant information, leading to more accurate and informative responses from the generator.
Challenges and Future Directions of RAG
Retrieval Augmented Generation, while incredibly promising, isn’t without its hurdles. The current iteration of RAG faces significant challenges that need addressing to unlock its full potential and ensure responsible implementation. These challenges range from technical limitations to ethical considerations, all impacting the reliability and trustworthiness of the systems.
The limitations of RAG stem from several key areas. First, the quality of the retrieved information directly impacts the quality of the generated response. If the knowledge base is incomplete, inaccurate, or biased, the AI will reflect these flaws. Second, the effectiveness of RAG depends heavily on the retrieval method used. Inefficient retrieval can lead to irrelevant or missing information, resulting in incomplete or misleading outputs. Finally, the computational cost of searching and processing large knowledge bases can be substantial, limiting the scalability and real-time application of RAG in resource-constrained environments.
Addressing Technical Limitations of RAG
Solutions to these technical limitations are actively being explored. Researchers are working on improving retrieval methods, such as developing more sophisticated embedding models and employing techniques like hybrid search that combine search with semantic similarity. Furthermore, advancements in efficient data structures and query optimization are aimed at reducing the computational burden of large-scale knowledge base searches. The development of more robust and explainable RAG models is also crucial for building trust and understanding how these systems arrive at their conclusions. For instance, future RAG systems could highlight the specific sources used in generating a response, allowing users to verify the information’s accuracy and provenance. This increased transparency would be a major step forward in building user confidence.
Ethical Considerations in RAG: Bias and Misinformation
The ethical implications of RAG are paramount. Because RAG systems learn from existing data, they can inherit and amplify biases present in the training data. This can lead to discriminatory or unfair outputs, particularly if the knowledge base reflects societal prejudices. Furthermore, the use of RAG to generate content can inadvertently spread misinformation if the underlying data contains inaccuracies or falsehoods. Mitigating these risks requires careful curation of the knowledge base, employing bias detection and mitigation techniques, and developing mechanisms for fact-checking and verification of generated content. Regular audits and updates of the knowledge base are also vital to ensure its ongoing accuracy and relevance. For example, a news aggregator using RAG could incorporate fact-checking algorithms to identify and flag potentially misleading information, preventing the dissemination of false narratives.
Future Trajectory of RAG Technology
Imagine a future where RAG systems seamlessly integrate with various applications, acting as intelligent assistants across multiple domains. The visual representation would depict a central, ever-expanding sphere representing the knowledge base, with numerous smaller spheres branching out, each representing a specific application (e.g., medical diagnosis, legal research, creative writing). These smaller spheres are dynamically connected to the central knowledge base, constantly receiving and updating information, resulting in a continuously evolving and increasingly sophisticated network. The connections between the spheres would be represented by vibrant, flowing lines, symbolizing the efficient and seamless flow of information. This network would be self-learning and adaptive, constantly refining its retrieval and generation capabilities, leading to increasingly accurate and nuanced responses. This vision signifies a move towards more context-aware, personalized, and trustworthy AI systems. Consider a scenario where a doctor uses RAG to access and synthesize the latest research on a rare disease, providing a more informed and efficient diagnosis for their patient. This highlights the transformative potential of RAG in diverse fields.
Case Studies
Real-world applications of Retrieval Augmented Generation (RAG) are proving its transformative potential across diverse sectors. These case studies showcase how RAG is solving complex problems and delivering tangible results, highlighting its versatility and effectiveness. Let’s delve into some compelling examples.
Case Study: Improved Customer Service at a Major Telecom Provider
This telecom giant integrated RAG into its customer service chatbot. Previously, the chatbot struggled with nuanced queries and often provided inaccurate information. By incorporating a knowledge base of FAQs, troubleshooting guides, and policy documents, the RAG-powered chatbot could now access and process relevant information in real-time, significantly improving response accuracy and customer satisfaction.
The approach involved fine-tuning a large language model (LLM) to retrieve and synthesize information from the company’s internal knowledge base. This allowed the chatbot to understand complex requests, locate the appropriate information within the vast knowledge base, and generate human-like responses. Results showed a 25% reduction in customer service call volume and a 15% increase in customer satisfaction scores.
Case Study: Enhanced Research Capabilities in Pharmaceutical Research, Unlocking ai potential the benefits and applications of retrieval augmented generation
A leading pharmaceutical company leveraged RAG to accelerate drug discovery. Researchers used RAG to sift through vast amounts of published research papers, clinical trial data, and internal research notes to identify potential drug candidates and predict their efficacy.
Their approach involved building a custom RAG system that could index and query a diverse range of data sources. The system allowed researchers to quickly identify relevant information, synthesize insights from multiple sources, and generate hypotheses more efficiently. This resulted in a 30% reduction in research time and the identification of three promising new drug candidates.
Case Study: Streamlined Legal Document Review at a Law Firm
A large international law firm implemented RAG to improve the efficiency of legal document review. Previously, lawyers spent countless hours manually reviewing contracts and legal documents. With RAG, they could quickly identify key clauses, potential risks, and relevant precedents, significantly speeding up the review process.
The firm’s approach involved creating a RAG system that could index and search a vast library of legal documents. The system allowed lawyers to quickly find relevant precedents, identify key clauses in contracts, and summarize complex legal documents. The result was a 40% reduction in document review time and a significant increase in lawyer productivity.
End of Discussion
Source: aiagent.vn
Retrieval Augmented Generation isn’t just a buzzword; it’s the next frontier in AI. By bridging the gap between raw computing power and reliable information, RAG empowers AI to become a truly valuable tool across numerous sectors. While challenges remain, the potential benefits are undeniable. As RAG technology matures and its applications expand, we can anticipate a future where AI is not only more intelligent but also significantly more trustworthy and ethically sound. The journey has just begun, and the possibilities are limitless.



{kind=link}